Purav PatelDecision Tree RegressorDecision Tree is both classification and regression problem solving algorithm.2 min read·Jul 3, 2021----
Purav PatelGradient Boostingit is one of the most powerful techniques for building predictive models.4 min read·Jun 26, 2021----
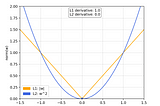
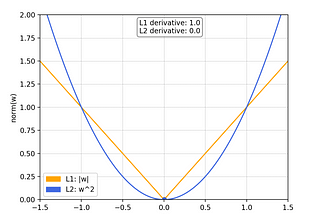
Purav PatelL1 and L2 RegularizationRegularization is a technique used for tuning the function by adding an additional penalty term in the error function. The additional term…3 min read·Jun 25, 2021----
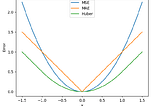
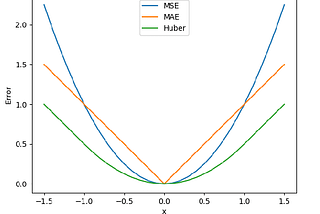
Purav PatelRegression loss and other important thingsMean Absolute Error, L1 loss3 min read·Jun 24, 2021----
Purav PatelIntroduction to Random ForestRandom Forest works on classification and Regression both problem statement.3 min read·Jun 23, 2021----
Purav PatelDecision Tree with Gini indexIf you don’t know about the Entropy follow this blog.3 min read·Jun 21, 2021----
Purav PatelIntroduction to Decision TreeA decision tree is a decision support tool that uses a tree-like model of decisions and their possible consequences, including chance event…4 min read·Jun 20, 2021----
Purav PatelIntroduction to Logistic RegressionIn statistics, the logistic model is used to model the probability of a certain class or event existing such as pass/fail, win/lose…4 min read·Jun 20, 2021----
Purav PatelLinear Regressionbefore diving deep into algorithm let’s talk about,4 min read·Jun 18, 2021----
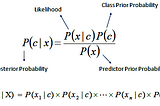
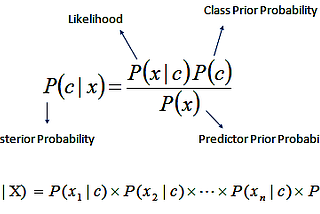
Purav PatelNaive Bayes ClassifierBefore going into depth of Naive Bayes, let’s talk about the his name,4 min read·Jun 17, 2021----